2.4 La structure du tagging
2.4.1 La structure de réseau
Comme vous avez pu le constater en explorant divers systèmes suggérés dans ce module, lorsqu’un système de tagging connaît du succès, il s’y établit un enchevêtrement de ressources, d’étiquettes et d’utilisateurs interconnectés, comme dans la figure suivante.
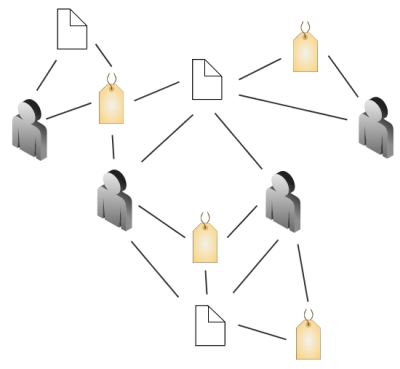
Il y a plusieurs manières de regarder ce réseau, et elles sont toutes instructives.
Autour des documents
Concentrons-nous premièrement sur les documents. On voit qu’autour de chaque document, il y a un certain nombre d’utilisateurs et un certain nombre d’étiquettes.
– Le voisinage d’utilisateurs fournit une réponse à la question « Qui s’intéresse à ce document ? »
– Le voisinage des étiquettes – le nuage d’étiquettes introduit plus tôt – nous fournit une indication de son contenu (ex. « architecture, design » et (ou) de ce que les gens en on fait (ex. « toread »).
Autour des étiquettes
Examinons deuxièmement les étiquettes. Le voisinage d’une étiquette est constitué : (1) de tous les documents pour lesquels au moins un utilisateur a jugé que l’étiquette s’appliquait ; (2) de tous les utilisateurs qui ont utilisé cette étiquette.
– L’ensemble de documents de ce voisinage est l’équivalent des résultats d’une recherche par mot-clé.
– L’ensemble des utilisateurs qui ont utilisé une étiquette donnée est intéressant à considérer. Il s’agit d’un groupe implicite, c’est-à-dire d’un groupe formé de gens qui ne se connaissent pas nécessairement tous, mais qui ont un intérêt en commun (en supposant en première approximation que l’étiquette a le même sens pour tous). Nous reviendrons sur ce concept dans la section sur la formation de groupes.
Autour des utilisateurs
Finalement, observons le voisinage des utilisateurs. Autour d’un utilisateur on retrouve son nuage d’étiquettes, qui reflète ses intérêts, ainsi qu’un nuage de documents, qui peut être vu comme une sorte de bibliothèque personnelle également indicative de ses intérêts.
Intersections et pivots
Considérons à présent deux étiquettes distinctes. Un certain nombre de documents se trouvent simultanément dans le voisinage de ces deux étiquettes - autrement dit, dans l’intersection de ces voisinages. En ajoutant des étiquettes, on se trouve à rendre plus spécifique la recherche par mot-clé et à limiter la taille de l’ensemble de documents.
Un jeu d’étiquettes peut également servir à définir un ensemble restreint d’utilisateurs qui ont beaucoup en commun : par exemple, les utilisateurs qui ont employé les étiquettes quebec, musique et libre.
Dans une perspective d’exploration, on peut voir les étiquettes comme des pivots qui permettent d’aller d’un document à un autre, ou d’un utilisateur à un autre. Par exemple, si on tombe sur un document fascinant dont on découvre qu’il a été étiqueté semanticweb, on risque d’en découvrir toute une grappe en prenant cette étiquette comme pivot.
Exercice 2D.
|
2.4.2 Pub/Sub et le réseau social
Nous avons introduit au module 1 les concepts de fil web et d’abonnement. Beaucoup de systèmes de tagging permettent une dynamique analogue, parfois à l’aide de fils web, parfois par des mécanismes internes d’abonnement.
On désigne ce patron général d’interaction par l’expression Pub/Sub. C’est l’un des éléments fondamentaux du web social, et il reviendra à plusieurs reprises dans le cours.
Les composantes fondamentales du patron Pub/Sub sont les suivantes :
– une source de messages (ou émetteur) ;
– un récepteur ;
– un mécanisme d’interrogation de sources (polling) ou d’envoi de messages (push).
On dira qu’un récepteur s’abonne au flux d’une source lorsqu’il utilise régulièrement (de façon automatisée) le mécanisme d’interrogation pour prendre connaissance des nouveaux messages qu’il n’a pas déjà reçus.
Dans le web social, les fils web constituent sans doute l’exemple le plus connu de Pub/Sub. La source de messages est le fichier RSS ; le récepteur est une personne qui s’abonne ; et le mécanisme d’interrogation consiste à utiliser le protocole HTTP et à traiter le contenu XML pour récupérer le fichier RSS ou Atom et y trouver les nouveaux items.
La plupart des systèmes de signets sociaux réalisent le patron Pub/Sub de la façon suivante. Lorsque vous visitez la page d’un utilisateur, vous voyez son flux d’information, et un bouton vous permet de vous y abonner si vous le souhaitez. La terminologie pour désigner cette action varie ; on parle parfois de « suivre » (follow) ou d’« ajouter à son réseau » un autre utilisateur. Il est généralement possible d’ajouter autant d’utilisateurs que l’on désire. Par la suite, le système vous fournit les nouvelles informations en provenance des sources que vous suivez.
Pub/Sub a un proche parent dans le « monde réel » : l’abonnement à des publications que l’on reçoit par la poste, ou l’abonnement à des listes de courriels (mailing lists). Cependant, une différence importante existe. Dans Pub/Sub, le récepteur ne s’identifie pas auprès de l’émetteur et il peut facilement rompre le lien d’abonnement et cesser de porter attention à une source qui ne l’intéresse plus.
Si vous donnez votre adresse postale ou électronique à quelqu’un, vous lui donnez en fait la permission de solliciter votre attention. Vous avez un problème s’il abuse de ce privilège en vous envoyant une avalanche de messages non désirés, ou encore en donnant ou en vendant votre adresse à d’autres parties. Vous pouvez toujours changer d’adresse, mais cela est problématique parce que cela invalide tous vos autres abonnements. Cette perte de contrôle du côté du récepteur n’est pas du tout un problème dans le patron Pub/Sub.
Lorsque des utilisateurs s’abonnent aux flux d’autres utilisateurs, on peut dire que Pub/Sub permet l’établissement d’un réseau social. La figure suivante représente un tel réseau de partage d’information sous la forme d’un graphe orienté.
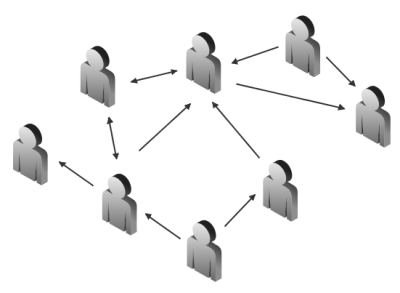
Plusieurs systèmes de tagging permettent à un récepteur non seulement de suivre le flux d’un utilisateur, mais aussi de surveiller le flux d’une étiquette : tous les items portant l’étiquette choisie sont présentés.
Un réseau de circulation d’information étendu par la présence d’étiquettes est illustré par le diagramme suivant.
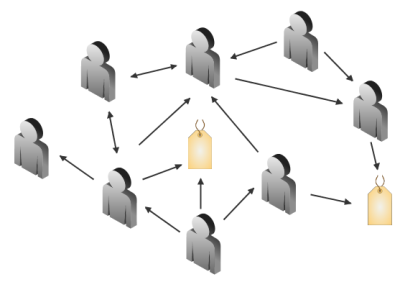
Notons que les étiquettes en elles-mêmes ne donnent évidemment jamais d’attention à quiconque. Par contre, il faut garder en tête que les flux associés aux étiquettes sont peuplés par des utilisateurs. En s’abonnant au flux d’une étiquette, on peut donc être exposé à des informations fournies par des utilisateurs qui nous sont encore inconnus.
2.4.3 Le filtrage social
Le filtrage interpersonnel
La flexibilité des mécanismes Pub/Sub permet à chaque utilisateur de choisir un ensemble différent de sources. Il est évident que le choix des sources détermine la « diète d’information » que recevra un utilisateur.
Devant un choix pratiquement illimité, que doit faire l’utilisateur ? Il est clair que le facteur qui limite ici l’utilisateur est l’attention. Il est impensable de s’abonner à toutes les sources qui existent !
Une lueur d’espoir réside par contre dans l’action de relais, dont voici une manifestation concrète : si Philippe suit Jonathan et que Jonathan suit Anne-Marie, une information diffusée par Anne-Marie peut rejoindre Philippe si Jonathan choisit de la diffuser à son tour.
En partageant une information qu’il tient d’une de ses sources, chaque utilisateur se trouve donc à exposer indirectement ses récepteurs à des sources qu’ils ne suivent pas eux-mêmes.
Étant donné la structure de réseau, il peut exister plusieurs chemins à travers le graphe entre deux participants donnés. On peut penser qu’en choisissant judicieusement ses sources, l’utilisateur peut espérer que les informations qui ont le plus de valeur pour lui le rejoignent, même si elles partent d’un point éloigné de lui dans la topologie du réseau.
Remarquons que cette dynamique a toujours existé dans les réseaux sociaux humains. La particularité du web social est que les mécanismes de la transmission d’information sont beaucoup plus explicites et que les coûts de communication extrêmement bas multiplient la puissance et la rapidité du réseau de distribution.
Il peut arriver que l’on s’intéresse particulièrement à un sujet plutôt qu’à une personne en particulier. En tel cas, il peut être intéressant de trouver une étiquette ou un ensemble d’étiquettes qui décrit bien le sujet, et de suivre les contenus qui se sont vu attribuer ces étiquettes.
Dans certains cas, cette stratégie fonctionne bien. Par exemple, si une poignée de personnes commencent à employer l’étiquette python pour relever des liens intéressants sur le langage de programmation du même nom, le flux associé à l’étiquette peut s’avérer intéressant à suivre pour un programmeur qui s’intéresse à ce langage.
En revanche, si un millier de personnes entrent en scène et se mettent à utiliser cette étiquette pour parler du reptile, le flux n’aura plus le même intérêt pour notre programmeur. Dans le langage de la théorie de l’information, on dira que le signal du flux se perd dans le bruit ambiant.
En ajoutant un filtrage interpersonnel, cependant, notre programmeur peut tout de même obtenir un flux intéressant. Il n’a en effet qu’à suivre l’étiquette en question chez quelques utilisateurs bien choisis dont le flux étiqueté python présente de la valeur à ses yeux.
Un autre scénario est celui de la dilution de la qualité : si une étiquette devient trop populaire, on a une situation où beaucoup d’utilisateurs se servent du terme pour des contenus peu inspirés. Ici, encore, la stratégie ci-dessus peut être appliquée.
La question demeure de savoir comment choisir les filtres humains. C’est une question cruciale et complexe qui sera abordée au module 4.