

Précision et rappel |
 |
On mesure l’efficacité d’une technique de recherche d’informations en utilisant deux mesures distinctes. Prenons comme scénario un système de recherche d’informations qui, à la suite d’une requête avec le mot pomme, retourne une liste de 60 documents. Sur 100 documents traitant du fruit « pomme », il en fournit 50, mais les 10 documents restants portent plutôt sur la compagnie Pomme et Fils qui vend des tournevis.
La précision donne le pourcentage de réponses correctes. Dans le cas de ce scénario, le pourcentage de réponses correctes est 50/60 ou 83 %.
Le rappel donne le pourcentage des réponses correctes qui sont données. Dans ce cas précis, le rappel est de 50 %.
À lire : L’article sur la précision et le rappel dans Wikipédia.
En pratique, il est facile de fournir un système avec un rappel de 100 % : il suffit de retourner la liste de tous les documents. Il est aussi facile d’obtenir une précision qui se rapproche de 100 % : il suffit de retourner aussi peu de documents possibles, sauf un ou deux documents dont on est certain de la pertinence.
En pratique, on cherche un bon compromis entre le rappel et la précision. Afin d’évaluer un système, on fait souvent un graphique du rappel par rapport à la pertinence (ou vice versa).
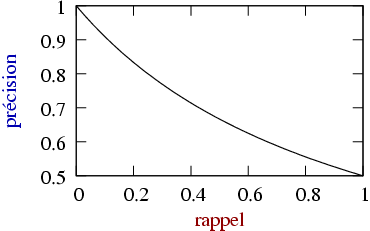
Dans certaines applications, le rappel est beaucoup plus important que la précision. Par exemple, lorsqu’il s’agit de trouver les courriels qui ne sont pas des pourriels, il est très important de trouver tous les courriels qui ne sont pas des pourriels ; il est cependant moins grave que certains pourriels survivent au filtrage.
Le contraire est parfois vrai. Supposons qu’on doive attribuer à des documents des mots-clés pour faciliter la recherche. On peut mesurer la qualité d’exécution de cette tâche en fonction du rappel (est-ce qu’on a trouvé tous les mots-clés qui s’appliquent ?) et de la précision (est-ce que tous les mots-clés attribués sont pertinents ?). Dans ce cas, la précision n’est pas très importante, mais on souhaite que tous les documents puissent être traités.
Comment choisir le meilleur compromis lorsque la précision et le rappel sont pratiquement d’égale importance ? Une des méthodes utilisées est de maximiser la moyenne harmonique de la précision et du rappel : ![]() . On appelle cette moyenne le score F.
. On appelle cette moyenne le score F.
Question
J’ai trois documents pertinents sur un total de 10 dans ma base de données. Un algorithme sélectionne 5 documents, dont deux sont pertinents, quel est le rappel et la précision ?
L’expérience de l’utilisateur
Malgré des années de travaux, il n’est pas certain que l’on sache mesurer l’efficacité d’un système de recherche d’informations du point de vue de l’utilisateur. Par exemple, le Probability Ranking Principle n’est qu’une hypothèse théorique avec peu de fondement expérimental. En fait, il a été démontré que les différentes tentatives faites pour apprécier l’expérience de l’utilisateur avec des mesures mathématiques sont un échec [1].
[1] Andrew Turpin, and Falk Scholer, User Performance versus Precision Measures for Simple Search Tasks, SIGIR’06.
