

Le filtrage collaboratif utilisateur-utilisateur |
 |
Filtrage par évaluation
Le filtrage collaboratif peut prendre plusieurs formes. Toute information sur les goûts ou les choix des utilisateurs peut servir, la seule condition étant qu’on doive regrouper des données concernant plusieurs utilisateurs pour aider chaque utilisateur.
Dans le cadre de ce cours, on distinguera deux types d’information utile : les choix binaires (« avoir acheté le livre x ») et les évaluations subjectives (« ce film vaut 5 sur 10 »). Le filtrage collaboratif doit aussi, souvent, tenir compte du contenu des objets : par exemple, les mots qui se trouvent dans un document donné. Cependant, l’information propre aux objets ne fait pas formellement partie du filtrage collaboratif ; on parle alors de systèmes hybrides. Dans cette leçon, nous nous attarderons aux cas où les évaluations sont explicites : l’utilisateur indique clairement son intention par un achat ou un vote. Cependant, certaines évaluations sont implicites : lorsqu’un utilisateur passe plus de 5 secondes sur une page web donnée avant de cliquer, on peut supposer que son intérêt a été suscité. Dans un sens, on pourrait presque considérer PageRank comme un exemple de filtrage collaboratif implicite, puisque certains utilisateurs choisissent de mettre des liens vers certaines pages web, votant donc implicitement pour de telles pages web.
Dans le contexte du filtrage utilisateur-utilisateur, seules les évaluations subjectives explicites nous intéressent : il est alors question de filtrage par évaluation parce qu’on utilise les évaluations subjectives des gens pour filtrer.
La matrice article-utilisateur
Le filtrage peut s’opérer sur plusieurs types d’objets, de biens, de services, de pages web, de documents, de gens, etc. L’important est d’avoir une correspondance entre des utilisateurs et des articles (ou produits). On peut représenter cette correspondance sous la forme d’une matrice article-utilisateur semblable à la matrice terme-document utilisée pour la recherche textuelle :
| Article 1 | Article 2 | Article 3 | Article 4 | |
| Jean | 7 | - | 8 | 7 |
| Marie | 6 | 5 | - | 2 |
| Pierre | - | 2 | 2 | 5 |
Nous supposons ici que les évaluations portent sur un total de 10, 2/10 représentant donc une mauvaise note, alors que 8/10 constitue une excellente note. Le tiret « - » représente l’absence d’évaluation. En effet, la plupart des utilisateurs ne vont accorder une note qu’à un très petit nombre d’articles. Amazon.com vend des millions de livres... mais combien de livres pensez-vous pouvoir noter dans votre vie ? Dans la matrice utilisateur-article, il ne pourrait y avoir qu’environ 1 %, ou moins encore, de cellules qui contiennent une information.
Distribution des notes
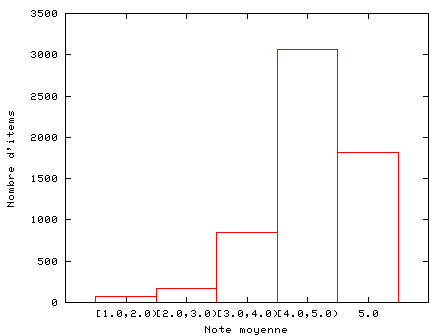
Dans une salle de cours, on s’attend à ce que les notes suivent une distribution normale (distribution « en cloche »). Lorsqu’on offre aux gens la possibilité d’évaluer des produits ou services sur le web, on constate que la distribution des notes n’est pas symétrique. En effet, on tend à se donner de la peine surtout pour indiquer que l’on aime quelque chose, et on met beaucoup moins d’efforts à noter les choses qu’on aime moins. Cela se comprend fort bien dans un contexte où nous avons une abondance de choix et d’information : il est plus facile de répertorier ce que l’on aime, que tout ce que l’on aime pas ou que l’on ne connaît pas.
En utilisant le service web d’Amazon, en 2004, j’ai téléchargé tous les cédéroms musicaux d’auteurs canadiens vendus sur amazon.com. Plusieurs de ces cédéroms avaient reçu des notes de la part des consommateurs. Voici la distribution des notes :
Les débuts du filtrage collaboratif
La méthode la plus élémentaire de filtrage collaboratif consiste tout simplement à faire la moyenne des notes obtenues par tous les articles et à suggérer, à tous les utilisateurs, les dix articles ayant obtenu les meilleures notes. Nous sommes tous familiers avec les « Top 10 » que l’on entend à la radio : dans la mesure où le « Top 10 » est basé sur les opinions d’un grand nombre d’auditeurs, il s’agit de filtrage collaboratif. Cependant, ce n’est pas du filtrage collaboratif personnalisé. En d’autres termes, tout le monde reçoit la même recommandation.
Corrélation de Pearson
La corrélation de Pearson entre deux vecteurs est une valeur entre -1 et 1. Deux vecteurs identiques sont parfaitement corrélés (corrélation = 1), alors que deux vecteurs opposés (![]() ) sont parfaitement anticorrélés (corrélation = -1). Les vecteurs
) sont parfaitement anticorrélés (corrélation = -1). Les vecteurs ![]() et
et ![]() ne sont pas corrélés du tout (corrélation = 0). Intuitivement, la corrélation entre deux choses nous donne une mesure de la « redondance ».
ne sont pas corrélés du tout (corrélation = 0). Intuitivement, la corrélation entre deux choses nous donne une mesure de la « redondance ».
Si ![]() est la moyenne des composantes d’un vecteur, alors la corrélation de Pearson est définie par :
est la moyenne des composantes d’un vecteur, alors la corrélation de Pearson est définie par :
= \frac{ (V-\overline{V})\cdot(W-\overline{W}) }{ \Vert V-\overline{V} \Vert \Vert W-\overline{W} \Vert }.")
Si ![]() ou
ou ![]() , la corrélation n’est pas définie par cette formule et on peut lui assigner la valeur nulle.
, la corrélation n’est pas définie par cette formule et on peut lui assigner la valeur nulle.
Similitude entre les utilisateurs
Reprenons la matrice article-utilisateur :
| Article 1 | Article 2 | Article 3 | Article 4 | |
| Jean | 7 | - | 8 | 7 |
| Marie | 6 | 5 | - | 2 |
| Pierre | - | 2 | 2 | 5 |
Chaque utilisateur peut être vu comme étant un « vecteur » incomplet : nous n’en connaissons pas toutes les composantes. Néanmoins, étant donné deux vecteurs incomplets, on peut limiter notre analyse aux seules composantes qu’ils ont en commun.
Par exemple, pour comparer Marie et Pierre, on omet les valeurs manquantes ou les articles que Marie et Pierre n’ont pas en commun. Nous avons alors les deux vecteurs suivants : ![]() et
et ![]() . La corrélation de Pearson est une mesure de la similarité entre deux vecteurs :
. La corrélation de Pearson est une mesure de la similarité entre deux vecteurs :
où le produit scalaire (![]() ) est calculé avec les articles que les deux utilisateurs ont en commun.
) est calculé avec les articles que les deux utilisateurs ont en commun.
Dans le cas de Marie, ![]() , et Pierre,
, et Pierre,
![]() . Si on ne retient que les composantes correspondantes aux articles 2 et 4 [1], les vecteurs sont donc
. Si on ne retient que les composantes correspondantes aux articles 2 et 4 [1], les vecteurs sont donc ![]() et
et ![]() , on a donc
, on a donc
\cdot (-1,2) }{\sqrt{(0.67,-2.33)\cdot(0.67,-2.33) (-1,2) \cdot (-1,2)}}=\frac{-5.33}{5.43}\approx -1.")
En d’autres termes, Marie et Pierre sont des « contraires » : l’un préfère l’article 4 et l’autre préfère l’article 2.
Pour calculer la corrélation entre Jean et Marie, on observe d’abord que la moyenne de Jean est 7.33. On a donc :
\cdot (-0.33,-0.33) }{\sqrt{(1.67,-2.33)\cdot(1.67,-2.33) (-0.33,-0.33) \cdot (-0.33,-0.33)}}=\frac{0.22}{1.33}\approx 0.16.")
En d’autres termes, Marie et Jean sont peu corrélés.
Prédiction comme moyenne pondérée
Supposons maintenant que nous souhaitions prédire les notes que donnerait Marie à l’article 3. Nous utilisons alors la formule suivante [2] :
 ( u_3 - \bar u)}{\sum_{u=\textrm{Jean},\textrm{Pierre}} \vert \textrm{Pearson} (\textrm{Marie}, u) \vert }")
où ![]() est la moyenne de toutes les notes
est la moyenne de toutes les notes
accordées par Marie (pour tous les articles !) et même chose pour ![]() qui
qui
est la moyenne des notes accordées par l’utilisateur ![]() (sur tous
(sur tous
les articles !).
Ce type de formule est ce qu’on appelle une moyenne pondérée. Dans le cas qui nous concerne, on
obtient la prédiction suivante [3] :
+0.16\times 0.66}{1+0.16} \approx 5.3.")
Cet algorithme est l’algorithme de base du filtrage collaboratif utilisateur-utilisateur par corrélation de Pearson. Pour autant
que tous les articles soient notés par au moins un utilisateur
ayant quelques articles en commun avec l’utilisateur courant, on peut
obtenir des prédictions efficaces pour tous les articles.
Amplification des similitudes
La corrélation de Pearson n’est pas la meilleure mesure de similarité pour le filtrage
collaboratif. De nombreuses expériences ont révélé qu’un très bon choix consiste à prendre la corrélation de Pearson à la puissance 2.5. Plus exactement, on
fait le calcul suivant : ![]() .
.
En Java, on pourra programmer cette modification comme ceci : ![]() .
.
La formule complète devient alors, dans notre exemple,

\vert \textrm{Pearson} (\textrm{Marie}, u)\vert ^{1.5} ( u_3 - \bar u) }{\sum_{u=\textrm{Jean},\textrm{Pierre}} \vert \textrm{Pearson} (\textrm{Marie}, u) \vert^{2.5} }.")
Dans le cas de notre exemple, avec l’utilisateur Marie, la prédiction demeure inchangée :
+0.01\times 0.66}{1+0.01} \approx 5.3")
où nous avons utilisé le fait que ![]() .
.
Cet algorithme simple a subi l’épreuve du temps et a été comparé à de multiples alternatives.
Si on utilise l’amplification des similitudes, la précision de l’algorithme est difficile à
surpasser. Dans la mesure où on prend une moyenne sur un grand nombre
d’utilisateurs, il est difficile pour des « brigands » de tricher
en essayant de promouvoir un article plutôt qu’un autre.
Référence :
– J. S. Breese, D. Heckerman, et C. Kadie. Empirical analysis of predictive algorithms for collaborative filtering, In Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence, Madison (WI), Morgan Kaufman Eds., 1998, p. 43-52.
Indépendance par rapport à l’échelle (matériel optionnel)
Dans l’algorithme décrit précédemment, un utilisateur qui
attribue des notes plus extrêmes (0 ou 10 sur 10) aura un
effet plus important qu’un utilisateur plus timide (qui met
des 3 ou 7 sur 10). Dans ce sens, ce n’est pas un algorithme
très « démocratique ». On a montré qu’il était possible
d’améliorer les résultats en « normalisant » les évaluations. La normalisation la plus efficace semble être la cote z : les évaluations d’un utilisateur sont normalisées afin que la moyenne soit zéro et l’écart-type 1 (![]() ).
).
– Daniel Lemire, Scale and Translation Invariant Collaborative Filtering Systems, Information Retrieval, 8 (1), January 2005, p. 129-150.
Cold start
Un problème connu sous le nom de cold start affecte les algorithmes de filtrage collaboratif
utilisateur-utilisateur. Comme nous l’avons vu, pour calculer la similitude entre deux utilisateurs,
il faut quand même avoir pas mal d’informations. Que faire lorsque l’utilisateur n’a noté que zéro,
un, deux ou trois articles ? En pratique, on retourne alors à la stratégie de la recommandation
non personalisée (le « Top 10 »).
Mise à l’échelle
Comme nous l’avons décrit ci-dessus, l’algorithme de filtrage utilisateur-utilisateur implique la comparaison avec tous
les utilisateurs. Si ![]() est le nombre d’articles,
est le nombre d’articles, ![]() le nombre d’utilisateurs et
le nombre d’utilisateurs et ![]()
le nombre d’articles notés par l’utilisateur courant, alors la complexité de l’algorithme
est ![]() . On voit que plus le nombre d’utilisateurs croît, plus l’algorithme
. On voit que plus le nombre d’utilisateurs croît, plus l’algorithme
devient lent, ce qui peut poser de sérieux problèmes si on a des millions de clients.
Une alternative efficace est de choisir, aléatoirement, ![]() utilisateurs avec qui on fait une comparaison. Le problème avec ce type de stratégie est que nous serons alors limités, dans nos prédictions, aux seuls articles notés par ces
utilisateurs avec qui on fait une comparaison. Le problème avec ce type de stratégie est que nous serons alors limités, dans nos prédictions, aux seuls articles notés par ces ![]() utilisateurs. Nous disons alors que notre « couverture » est limitée. L’avantage de choisir aléatoirement les utilisateurs, outre la simplicité de l’approche, est que les dégâts possibles causés par des utilisateurs frauduleux (qui tentent de pervertir le système) sont limités.
utilisateurs. Nous disons alors que notre « couverture » est limitée. L’avantage de choisir aléatoirement les utilisateurs, outre la simplicité de l’approche, est que les dégâts possibles causés par des utilisateurs frauduleux (qui tentent de pervertir le système) sont limités.
Référence :
– E. Ogston, A. Bakker, and M. van Steen, On the Value of Random Opinions in Decentralized Recommendation, Proc. 6th IFIP Int’l Conf. on Distributed Applications and Interoperable Systems (DAIS), Bologna (Italy), June 2006.
[1] Notez qu’il n’y a pas d’erreur. On calcule bien la moyenne sur toutes les composantes, alors qu’on fait le produit scalaire seulement sur les articles en commun. Ce n’est pas la définition traditionnelle de la corrélation de Pearson.
[2] Par convention, $\sum_u=\textrmJean,\textrmPierre$ est la somme du cas où $u=\textrmJean$ avec le cas $u=\textrmPierre$.
[3] On utilise les faits suivants : $\textrmPearson (\textrmMarie, \textrmJean)\approx0.16$, $\textrmPearson (\textrmMarie, \textrmPierre)\approx-1$, $\textrmPierre_3=2$, $\textrmJean_3=8$, $\overline \textrmPierre=3$, et $\overline \textrmJean\approx7.33$.
