

Arbres et tableaux de suffixes |
 |
Autres structures
L’index inversé est idéal lorsqu’on désire chercher des mots dans des documents. On peut assez facilement le compresser et il est généralement facile de l’implémenter de façon très efficace. C’est ce qui explique que c’est la méthode privilégiée pour indexer du texte.
Cependant, l’index inversé ne permet pas de faire la recherche rapide de motifs ou de compter rapidement le nombre d’occurrences d’un motif donné. Les expressions régulières permettent de chercher des motifs arbitraires, mais l’opération est en pratique assez lente [1] ; on peut vouloir accélérer considérablement cette recherche. On peut aussi vouloir faire de l’exploration de textes (text mining, en anglais) pour trouver les chaînes de caractères fréquentes ou rares le plus rapidement possible. Il existe deux structures fréquemment utilisées pour ce type d’application :
- les arbres de suffixes [2] qui sont très rapides, mais qui demandent beaucoup d’espace de stockage ;
- les tableaux de suffixes qui sont un peu moins rapides, mais qui demandent moins d’espace de stockage.
Ces structures utilisent le concept de « suffixe ». L’ensemble des suffixes d’une chaîne de caractères est tout simplement l’ensemble des chaînes de caractères débutant à un point arbitraire de la chaîne et allant jusqu’à la fin de la chaîne. Par exemple, la chaîne « montréal » comporte les suffixes suivants :
- montréal
- ontréal
- ntréal
- tréal
- réal
- éal
- al
- l
La recherche de motifs est équivalente à la recherche dans les suffixes. Ainsi, si je cherche le motif « ntr » dans montréal, il suffit de chercher les suffixes débutant par « ntr » (« ntréal ») et d’en trouver les positions.
Autres structures : les arbres de suffixes
Un arbre de suffixes est une structure en arbre où chaque nœud de l’arbre est une chaîne de caractères où, à partir de la racine et jusqu’à chaque « feuille », on énumère l’ensemble des suffixes ; chaque nœud de l’arbre qui n’est pas une « feuille » possède au moins deux « descendants » (voir l’exemple). On peut construire un arbre de suffixes en temps ![]() où
où ![]() est la longueur de la chaîne de caractères. Cependant, l’arbre de suffixes peut requérir beaucoup d’espace de stockage.
est la longueur de la chaîne de caractères. Cependant, l’arbre de suffixes peut requérir beaucoup d’espace de stockage.
Étant donné la chaîne « laval », nous avons les suffixes suivants :
- laval
- aval
- val
- al
- l
Voici l’arbre de suffixes correspondant :
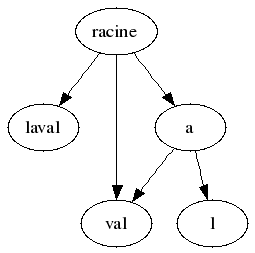
Notez bien qu’on a choisi une chaîne courte, et comprenant peu de caractères différents. Une chaîne plus longue, contenant des caractères variés, générerait un arbre complexe.
Pour utiliser un arbre de suffixes en recherche de motifs, on note tout simplement la position de chaque nœud dans la chaîne :
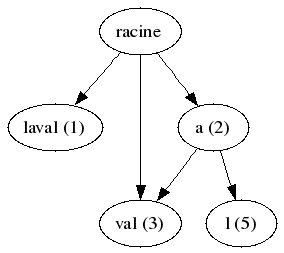
Ainsi, pour trouver la chaîne « al », il suffit de partir de la racine, de choisir le nœud « a » (position 2) et de voir qu’il est suivi d’un nœud « l ». On voit qu’il suffit de se déplacer dans l’arbre de nœud en nœud, ce qui peut être fait assez rapidement.
L’implémentation d’un arbre de suffixes peut être assez complexe et il y a plusieurs techniques et structures de données différentes qui peuvent être utilisées.
On utilise beaucoup les arbres de suffixes en bio-informatique pour étudier l’ADN et divers autres types de séquences.
Pour plus d’information, voir http://www.csse.monash.edu.au/~lloy...
Autres structures : les tableaux de suffixes
L’approche par tableaux de suffixes est une approche différente. Au lieu de construire un arbre avec les suffixes, on fait le tri (en ordre « alphabétique ») des suffixes.
Astuce : Il y a une correspondance unique entre les entiers de 1 jusqu’à n où n est la longueur de la chaîne. Si on veut stocker l’ensemble des suffixes, on peut donc se contenter de stocker des entiers et ainsi économiser pas mal d’espace.
Par exemple, si on reprend l’exemple de la chaîne « laval », et de ses suffixes :
- laval
- aval
- val
- al
- l
on peut les trier comme suit :
– 4 : al
– 2 : aval
– 5 : l
– 1 : laval
– 3 : val
Il suffit alors de stocker le tableau « 4,2,5,1,3 » qui forme le « tableau de suffixes ».
On peut alors chercher un motif par recherche binaire. La recherche binaire est une astuce simple pour trouver chaque élément dans un tableau trié ; vous la connaissez sans doute intuitivement :
- on compare l’élément x avec l’élément y se trouvant au milieu du tableau : s’ils sont identiques, l’algorithme se termine ;
- si l’élément x est plus petit que y, on recommence en cherchant x dans la première moitié du tableau ;
- si l’élément x est plus grand que y, on recommence en cherchant x dans la second moitié du tableau.
La recherche binaire s’effectue dans un temps logarithmique.
Afin d’accélérer encore plus la recherche dans les suffixes, notamment pour éviter des comparaisons coûteuses entre des chaînes de caractères très longues, on adjoint au tableau de suffixes des structures secondaires.
On peut construire un tableau de suffixes en temps O(n) [3].
Implémentations logicielles :
– External Memory Suffix Array Construction (STXXL) (en anglais)
– Sary (en anglais ou en japonais)
Application : le calcul rapide des fréquences des n-grammes
Un problème courant en modélisation de la langue est le calcul des fréquences des divers n-grammes. On peut faire ce calcul très efficacement en utilisant un arbre de suffixes.
Prenons le tableau de suffixes de « lalala ».
– a
– ala
– alala
– la
– lala
– lalala
Maintenant, pour chaque position, nous allons calculer la longueur du préfixe maximal que le suffixe a en commun avec le suffixe suivant (par exemple, ordure et ordinateur ont comme préfixe maximal « ord ») :
– a (1)
– ala (3)
– alala (0)
– la (2)
– lala (4)
– lalala
Par exemple, les suffixes « alala » et « alala » n’ont aucun préfixe en commun, d’où le 0.
Avec cette information, on peut calculer rapidement le nombre et la fréquence des n-grammes. Supposons que je veuille trouver tous les bigrammes et leur fréquence. Je pars de « a », que je passe parce qu’il ne peut constituer un bigramme. J’arrive à « ala » qui débute par le bigramme « al ». Je note qu’il a 3 caractères en commun avec le suffixe suivant. Je conclus donc que « al » apparaît deux fois dans le texte. Je passe donc immédiatement à « la » qui débute avec le bigramme « la ». Comme le suffixe a 2 caractères en commun avec le suffixe suivant qui, lui-même, a 4 caractères en commun avec le suffixe qui le suit, j’en conclus que le bigramme « la » apparaît 3 fois.
– al (2 fois)
– la (3 fois)
Référence : M. Nagao, and S. Mori, A New Method of N-gram Statistics for Large Number of n and Automatic Extraction of Words and Phrases from Large Text Data of Japanese. L’algorithme Nagao-Mori a été implémenté en Open Source par Zhang Le.
[1] Il faut parcourir tous les documents à chaque nouveau motif !
[2] Un suffixe est ici toute chaîne de caractères ou de mots qui termine une autre chaîne, voir la définition donnée par wikipédia.
[3] Wing-Kai Hon Sadakane, and K. Wing-Kin Sung, Breaking a time-and-space barrier in constructing full-text indices, Foundations of Computer Science, 2003.
