

La logistique d’un moteur de recherche web |
 |
Recherche locale et recherche sur le web
Chercher des documents dans un ensemble connu, comme au sein d’une entreprise, est relativement « facile ». En comparaison, la recherche dans un ensemble aussi distribué et dynamique que le web est beaucoup plus difficile. Alors qu’un simple serveur contenant un logiciel de recherche d’informations suffit souvent à répondre aux besoins de recherche au sein d’une entreprise, la recherche sur le web nécessite de l’équipement informatique beaucoup plus distribué et beaucoup plus coûteux. Il faut aussi attaquer le problème de l’abondance d’information avec des astuces nouvelles. Pour l’essentiel, le secret de l’efficacité des moteurs de recherche sur le web est le parallélisme, qu’on peut définir comme étant la capacité qu’ont plusieurs microprocesseurs de travailler de concert pour résoudre rapidement un problème. L’astuce n’est pas nouvelle : il y a longtemps que la plupart des ordinateurs utilisent des processeurs spécialisés pour les graphiques et d’autres processeurs, pour le son. La différence est maintenant que les quantités d’informations numériques sont inégalées dans l’histoire de l’humanité et que la tolérance des utilisateurs quant à la latence est très faible.
Chargement des pages web
Un moteur de recherche sur le web doit charger périodiquement toutes les pages web qu’il désire indexer. Si on compte environ une seconde pour le chargement d’une page web, un seule machine ne pourrait que charger 85 mille pages par jour [1]. Les moteurs de recherche ont plutôt plusieurs agents [2] qui chargent les pages web en parallèle. Ils se répartissent les adresses URL à charger de façon équitable pour qu’une même URL ne soit pas chargée deux fois : un modèle simple pourrait être qu’un agent charge toutes les URL débutant par « A », un autre, toutes les URL débutant par « B », et ainsi de suite. En pratique, on définit plutôt une fonction de hachage qui convertit l’URL en un certain nombre [3] : ce nombre détermine l’agent qui sera utilisé.
Les agents doivent veiller à ne pas surcharger les serveurs web en plaçant trop de requêtes en même temps sur un même serveur web. Ils doivent aussi respecter le fichier d’exclusion des robots (robot.txt).
Il faut aussi recouper le contenu dupliqué : si un auteur publie le même document sur dix sites différents, le moteur de recherche doit impérativement n’indexer qu’une seule des copies. Il n’est pas nécessairement facile, étant donné des milliards de pages web, de trouver de tels doubles, surtout quand le contenu exact des pages peut varier légèrement !
Finalement, il faut pouvoir détecter les pages web qui n’ont pour but que de tromper le moteur de recherche (pourriel, spam en anglais).
Le parallélisme
Peu de services web exigent autant de calculs qu’un moteur de recherche. Selon Google, une requête donnée exige en moyenne la lecture de plusieurs mégaoctets de données et utilise des dizaines de milliards d’instructions machine [4].
On peut imaginer que la solution serait de construire des ordinateurs gigantesques et très puissants. Ce serait un peu comme construire d’énormes autoroutes pour traiter le trafic des requêtes web. La solution retenue par la compagnie Google est plutôt de brancher des centaines de milliers de PC peu coûteux. Si chaque ordinateur en lui-même n’est pas très puissant, l’ensemble répond bien à la demande : plusieurs requêtes simples peuvent être traitées en paralèlle. Par ailleurs, un seul ordinateur très puissant, mais avec un unique microprocesseur, devrait traiter chaque requête une à une. Le résultat net serait un embouteillage monstre et un système fragile : imaginons que cet ordinateur surpuissant tombe en panne ! Pour reprendre l’analogie de l’autoroute, la solution de Google correspond plutôt à la construction de milliers de petites routes évitant soigneusement les goulots d’étranglement.
Quand une route est congestionnée ou en travaux, on redirige rapidement le trafic vers les autres routes parce qu’on en a un grand nombre.
Quand un utilisateur saisit une requête, telle que http://www.google.com/search?q=uqam, le navigateur doit d’abord obtenir une adresse IP pour le nom de domaine : « www.google.com». C’est à cette étape que Google choisit vers quelles machines la requête est acheminée. Google a plusieurs centres partout dans le monde et les requêtes sont distribuées en évitant les centres qui sont surchargés, mais en tentant aussi de traiter les requêtes localement pour éviter les délais causés par la distance. Dans chaque centre, la requête est d’abord reçue par un routeur qui planifie comment la requête sera traitée. Il faut consulter un index inversé qui donne, pour chaque terme, la liste des documents où il apparaît. S’il y a plus d’un mot-clé dans la requête, il faut alors faire l’intersection des listes de documents. Finalement, il faut calculer le degré de pertinence de chaque document, ce qui déterminera l’ordre d’apparition des documents. Le problème est que l’index inversé pour l’ensemble du web est énorme : plusieurs téraoctets [5] Heureusement, le traitement peut être fait en parallèle. Il suffit de partitionner le web en morceaux contenant une fraction des documents [6]. Chaque centre de traitement comporte plusieurs machines s’occupant exclusivement d’une partie du web qui leur est attribuée. À cause de cette stratégie, il faut comprendre que chaque centre de traitement stocke plusieurs copies du web ! Sur l’ensemble de la planète, un moteur de recherche comme Google doit donc stocker des centaines, voire des milliers de copies du web !
Les index inversés et toutes les autres bases de données utilisées sont destinés à la lecture seulement. On peut donc plus facilement optimiser le traitement pour obtenir des requêtes très rapides. Les mises à jour sont faites en mettant hors ligne une partie du système.
Avec une telle méthodologie, la vitesse relative de chaque machine importe peu. Si les machines sont plus puissantes, on peut découper le web en plus grandes parties, sinon, on peut aussi bien utiliser des parties plus petites. Les calculs se font, le plus possible, localement, sur chaque petite machine.
Par contre, avec beaucoup de machines peu coûteuses, les bris sont fréquents. Afin de contrecarrer les effets des pannes, il faut que le système d’exploitation et les systèmes de fichiers soient très robustes. À cette fin, la société Google a développé son propre système de fichiers qu’elle a intégré au système d’exploitation Linux. Le « Google File System » permet de stocker les fichiers de façon distribuée et robuste [7].
Le modèle MapReduce
Une des innovations de Google, liée à la conception de leur moteur de recherche, est le modèle « MapReduce » qui est une façon particulièrement efficace d’effectuer certains calculs sur de grands ensembles en utilisant plusieurs machines [8] La programmation fonctionnelle utilise souvent deux opérations fondamentales :
– l’opération « map » applique à tous les éléments d’un ensemble une certaine fonction. Par exemple, la fonction ![]() appliquée au vecteur
appliquée au vecteur ![]() donne
donne ![]() .
.
– l’opération « reduce » applique aux deux premiers éléments d’un ensemble une certaine fonction et les remplace par le résultat de cette fonction et, ainsi de suite, jusqu’à ce qu’il n’y ait plus qu’un seul élément. La fonction ![]() appliquée au vecteur
appliquée au vecteur ![]() donne la valeur
donne la valeur ![]() (la somme des valeurs dans le tableau !). En effet, comme première étape, l’opération « reduce » remplacera le tableau
(la somme des valeurs dans le tableau !). En effet, comme première étape, l’opération « reduce » remplacera le tableau ![]() par
par ![]() puis
puis ![]() .
.
Il se trouve qu’il est souvent possible de découper des calculs en deux phases, une première phase « map » suivie d’une phase « reduce ». En effet, supposons que vous vouliez calculer combien de valeurs négatives on trouve dans un tableau donné. L’opération « map » pourrait transformer les valeurs négatives en la valeur 1, alors que les valeurs positives ou nulles deviendraient 0. Il suffit ensuite de calculer la somme du résultat, ce qui se fait très bien en utilisant la fonction d’addition. L’opération « map » est alors très souvent parallélisable.
De façon plus générale, on peut appliquer le paradigme MapReduce quand notre ensemble de données est constitué d’éléments prenant la forme de paires (clé, valeur), par exemple « (document 12, "contenu du document") ».
Si on veut compter toutes les occurrences d’un mot, on peut le faire comme suit...
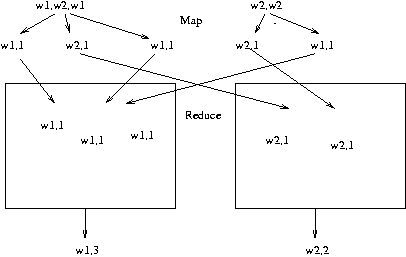
– La fonction « map » prend les documents ainsi que leurs contenus, et en extrait chaque mot rencontré. Par exemple, étant donné un document contenant le texte « w1 w2 w1 w3 w2 w1 », la fonction « map » générera les paires clé-valeur suivantes : « (w1,1) (w2,1) (w1,1) (w3,1) (w2,1) (w1,1) ». Notez qu’il est très facile de faire ce traitement en parallèle. Par exemple, chaque document peut être traité séparément.
– La fonction « reduce » calcule ensuite, pour chaque clé (chaque mot), la somme. Ainsi, étant donné les paires clé-valeur « (w1,1) (w2,2) (w1,1) (w3,1) (w2,1) (w1,1) », il calculera « (w1,3) (w2,2) (w3,1) ». Encore une fois, le calcul peut être fait en parallèle : un processeur pourrait s’occuper du mot « w1 », alors que les mots « w2 » et « w3 » seraient confiés à un autre processeur après une phase de tri.
Logiciel « Open Source »
Il existe un clone « Open Source » de MapReduce appelé hadoop. Nutch est, quant à lui, un outil d’indexation web. En février 2008, la société Yahoo ! a créé un réseau de calcul comprenant 10,000 processeurs avec Hadoop [9].
Anecdote. En 2008, Hadoop a gagné le Terabyte Sort Benchmark : un ensemble de serveurs utilisant Hadoop a réussi à trier 1 teraoctet de données en 209 secondes. L’ensemble de test est constitué de 10 milliards d’objets de 100 octets.
[1] David Hawking, Web Search Engines Part 1, IEEE Computer, June 2006.
[2] Agent : composant logiciel.
[3] En Java, voir la méthode hashCode de l’objet String.
[4] L.A. Barroso, J. Dean, and U. Hölzle, Web Search for a Planet : The Google Cluster Architecture, IEEE Micro, vol. 23(2), March/April 2003, p. 22-28.
[5] Pour traiter 8 milliards de pages web, il faut probablement, au minimum, 100 téraoctets, soit 100 000 gigaoctets ou environ 1 000 disques de 100 gigaoctets !
[6] En anglais, on appelle ces morceaux du web, des index shards.
[7] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System, 19th ACM Symposium on Operating Systems Principles, Lake George (NY), October 2003.
[8] Jeffrey Dean and Sanjay Ghemawat, MapReduce : Simplified Data Processing on Large Clusters,
OSDI’04 : Sixth Symposium on Operating System Design and Implementation, San Francisco (CA), December 2004.
[9] Eric Baldeschwieler, Yahoo ! Launches World’s Largest Hadoop Production Application, 19 février 2008
